
對硅谷和硅谷科技公司的十四問
從硅谷公司哪家強,到人人在議的泡沫問題,大數據和人工智能如何結合?2015 年的科技前瞻是怎樣一副圖景?來自硅谷的 Coursera 軟件工程師董飛將其近日在斯坦福公開講座上的干貨和各種場合的問答整理出來和大家分享。文中有他的一手從業經驗,也有其對親身就職或深度研究過的一些公司具體分析,如 Hadoop、Amazon、LinkedIn 等。
1、目前硅谷最火最有名的高科技創業公司都有哪些?
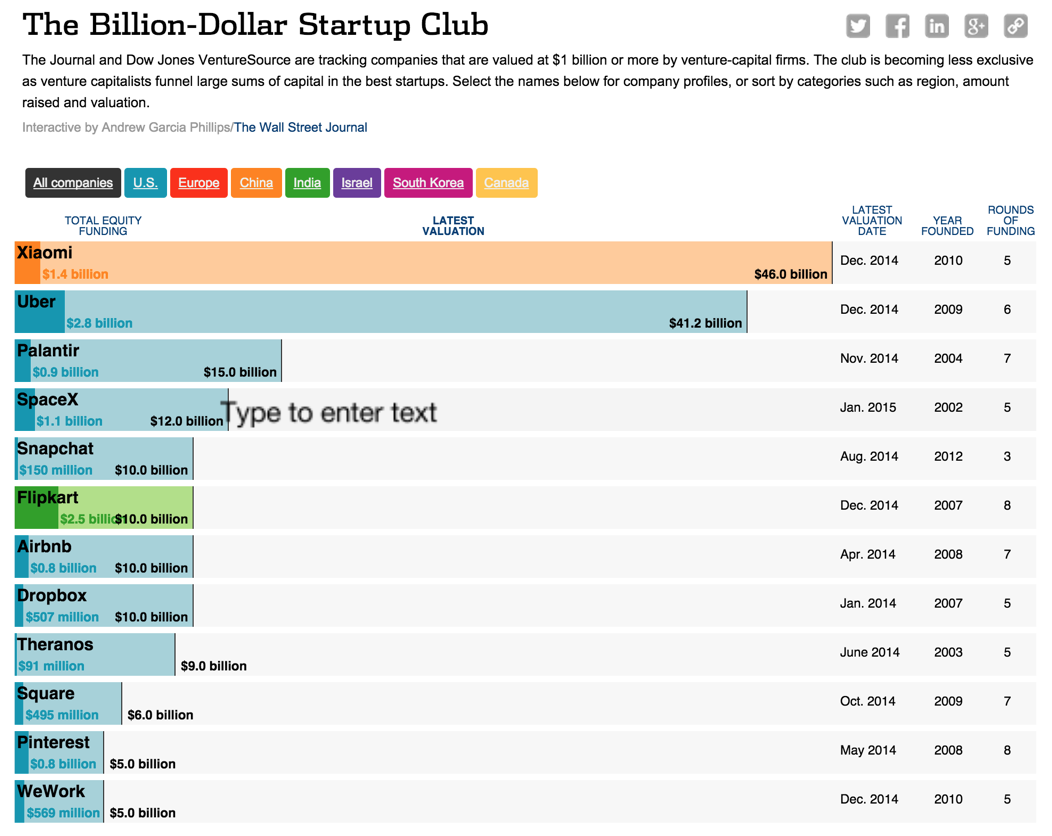
在硅谷大家非常熱情的談創業談機會,我也通過自己的一些觀察和積累,看到了不少最近幾年涌現的熱門創業公司。我給大家一個列表,這個是華爾街網站的全世界創業公司融資規模評選。它本來的標題是 billion startup club,我在去年國內講座也分享過,不到一年的時間,截至到 2015 年 1 月 17 日,現在的排名和規模已經發生了很大的變化。
首先估值在 10 Billlon 的達到了 7 家,而一年前一家都沒有。第二;第一名是中國人家喻戶曉的小米;第三,前20名中,絕大多數(8 成在美國,在加州,在硅谷,在舊金山!)比如 Uber, Airbnb, Dropbox, Pinterest;第四,里面也有不少相似模式成功的,比如 Flipkart 就是印度市場的淘寶,Uber 與 Airbnb 都是共享經濟的范疇。所以大家還是可以在移動 (Uber),大數據(Palantir),消費級互聯網,通訊 (Snapchat),支付 (Square),O2O App 里面尋找下大機會。這里面很多公司我都親自面試和感受過他們的環境。
2、有如此之多的高估值公司,是否意味著存在很大的泡沫?
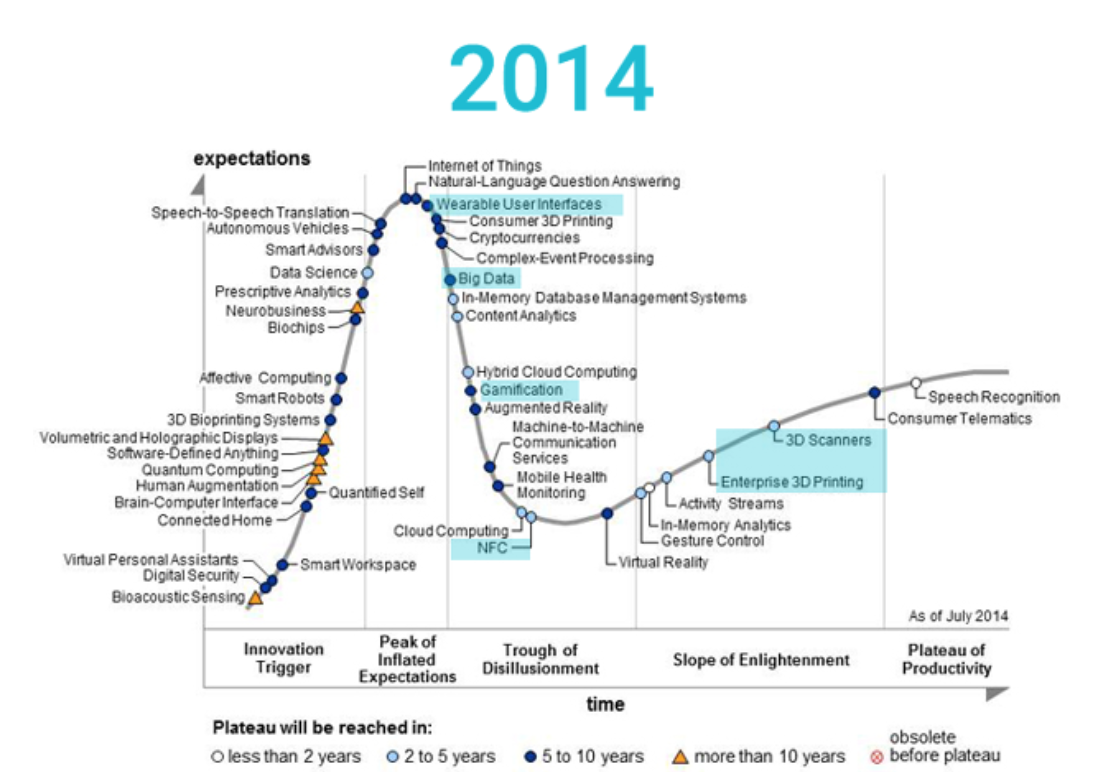
看了那么多高估值公司,很多人都覺得非常瘋狂,這是不是很大泡沫了,泡沫是不是要破了,是很多人的疑問。我認為在硅谷這個充滿夢想的地方,投資人鼓勵創業者大膽去做同樣也助長了泡沫,很多項目在幾個月的時間就會估值翻 2,3 倍,如 Uber,Snapchat 上我也驚訝于他們的巨額融資規模。那么這張圖就是講“新興技術炒作”周期,把各類技術按照技術成熟度和期望值分類。
創新萌芽 Innovation Trigger”、“期望最頂點 Peak ofInflated Expectation”、“下調預期至低點 Trough of Disillusion”、“回歸理想 Slope ofEnlightenment”、“生產率平臺 Plateau of Productivity”,越往左,技術約新潮,越處于概念階段;越往右,技術約成熟,約進入商業化應用,發揮出提高生產率的效果。縱軸代表預期值,人們對于新技術通常會隨著認識的深入,預期不斷升溫,伴之以媒體炒作而到達頂峰;隨之因技術瓶頸或其他原因,預期逐漸冷卻至低點,但技術技術成熟后,期望又重新上升,重新積累用戶,然后就到了可持續增長的健康軌道上來。
Gartner 公司每年發布技術趨勢炒作圖。今年和去年的圖對比顯示,物聯網、自動駕駛汽車、消費級 3D 打印、自然語言問答等概念正在處于炒作的頂峰。而大數據已從頂峰滑落,NFC 和云計算接近谷底。
3、未來,高科技創業的趨勢是什么?

我先提一個最近看的一部電影《Imitation Game》,講計算機邏輯的奠基者艾倫圖靈(計算機屆最高獎以他命名)艱難的一生,他當年為破譯德軍密碼制作了圖靈機為二戰勝利作出卓越貢獻,挽回幾千萬人的生命,可在那個時代因為同性戀被判化學閹割,自殺結束了短暫的 42 歲生命。他的一個偉大貢獻就是在人工智能的開拓工作,他提出圖靈測試(Turing Test),測試某機器是否能表現出與人等價或無法區分的智能。
今天人工智能已經有了很大進步,從專家系統到基于統計的學習,從支持向量機到神經網絡深度學習,每一步都帶領機器智能走向下一個階梯。
在 Google 資深科學家吳軍博士(數學之美,浪潮之巔作者),他提出當前技術發展三個趨勢,第一,云計算和和移動互聯網,這是正在進行時;第二,機器智能,現在開始發生,但對社會的影響很多人還沒有意識到;第三,大數據和機器智能結合,這是未來時,一定會發生,有公司在做,但還沒有太形成規模。他認為未來機器會控制 98% 的人,而現在我們就要做個選擇,怎么成為剩下的 2%?
4、為什么大數據和機器智能結合的未來一定會到來?
其實在工業革命之前(1820 年),世界人均 GDP 在 1800 年前的兩三千年里基本沒有變化,而從 1820 年到 2001 年的 180 年里,世界人均 GDP 從原來的 667 美元增長到 6049 美元。由此足見,工業革命帶來的收入增長的確是翻天覆地的。這里面發生了什么,大家可以去思考一下。但人類的進步并沒有停止或者說穩步增長,在發明了電力,電腦,互聯網,移動互聯網,全球年 GDP 增長從萬分之 5 到 2%,信息也是在急劇增長,根據計算,最近兩年的信息量是之前 30 年的總和,最近 10 年是遠超人類所有之前累計信息量之和。在計算機時代,有個著名的摩爾定律,就是說同樣成本每隔 18 個月晶體管數量會翻倍,反過來同樣數量晶體管成本會減半,這個規律已經很好的 match 了最近 30 年的發展,并且可以衍生到很多類似的領域:存儲、功耗、帶寬、像素。
馮諾伊曼是 20 世紀最重要的數學家之一,在現代計算機、博弈論和核武器等諸多領域內有杰出建樹的最偉大的科學全才之一。他提出(技術)將會逼近人類歷史上的某種本質的奇點,在那之后全部人類行為都不可能以我們熟悉的面貌繼續存在。這就是著名的奇點理論。目前會越來越快指數性增長,美國未來學家 Ray Kurzweil 稱人類能夠在 2045 年實現數字化永生,他自己也創辦奇點大學,相信隨著信息技術、無線網、生物、物理等領域的指數級增長,將在 2029 年實現人工智能,人的壽命也將會在未來 15 年得到大幅延長。
5、國外值得關注的大數據公司都有哪些?國內又有哪些?
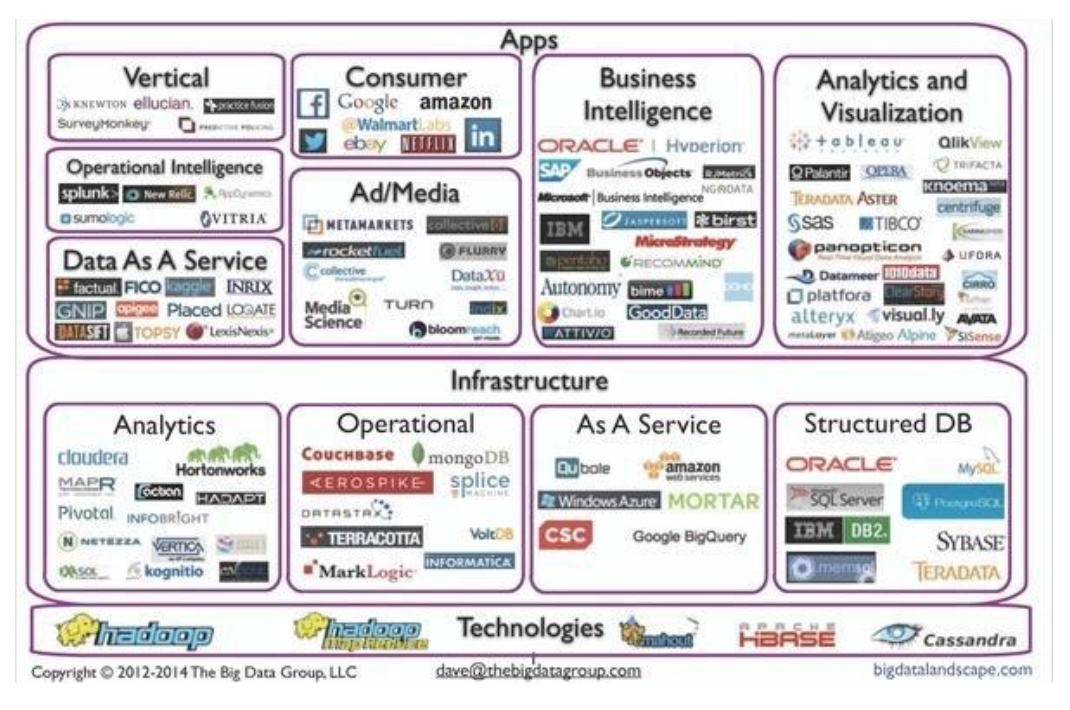
這是 2014 年總結的 Big Data 公司列表,我們大致可以分成基礎架構和應用,而底層都是會用到一些通用技術,如 Hadoop,Mahout,HBase,Cassandra,我在下面也會涵蓋。我可以舉幾個例子,在分析這一塊,cloudera,hortonworks,mapr 作為 Hadoop 的三劍客,一些運維領域,mangodb,couchbase 都是 nosql 的代表,作為服務領域 AWS 和 Google BigQuery 劍拔弩張,在傳統數據庫,Oracle 收購了 MySQL,DB2 老牌銀行專用,Teradata 做了多年數據倉庫。上面的 Apps 更多,比如社交消費領域 Google, Amazon, Netflix, Twitter, 商業智能:SAP,GoodData,一些在廣告媒體領域:TURN,Rocketfuel,做智能運維 sumologic 等等。去年的新星 Databricks 伴隨著 Spark 的浪潮震撼 Hadoop 的生態系統。
對于迅速成長的中國市場,大公司也意味著大數據,BAT 三家都是對大數據的投入也是不惜余力。
我 5 年前在百度的時候,就提出框計算的東東,最近兩年他們成立了硅谷研究院,挖來 Andrew Ng 作為首席科學家,研究項目就是百度大腦,在語音、圖片識別大幅提高精確度和召回率,最近還做了個無人自行車,非常有趣。騰訊作為最大的社交應用對大數據也是情有獨鐘,自己研發了 C++ 平臺的海量存儲系統。淘寶去年雙十一主戰場,2 分鐘突破 10 億,交易額突破 571 億,背后是有很多故事,當年在百度做 Pyramid(按 Google 三輛馬車打造的金字塔三層分布式系統)的有志之士,繼續在 OceanBase 創造神話。而阿里云當年備受爭議,馬云也懷疑是不是被王堅忽悠,最后經歷了雙十一的洗禮證明了阿里云的靠譜。小米的雷軍對大數據也是寄托厚望,一方面這么多數據幾何級數增長,另一方面存儲帶寬都是巨大成本,沒價值就會破產。
6、Hadoop 是現今最流行的大數據技術,在它出現的當時,是什么造成了 Hadoop 的流行?當時 Hadoop 具有哪些設計上的優勢?
看 Hadoop 從哪里開始的,不得不提 Google 的先進性,在 10 多年前,Google 出了 3 篇 paper 論述分布式系統的做法,分別是 GFS, MapReduce, BigTable, 非常 NB 的系統,但沒人見過,在工業界很多人癢癢的就想按其思想去仿作,當時 Apache Nutch Lucene 的作者 Doug Cutting 也是其中之一,后來他們被 Yahoo 收購,專門成立 Team 去投入做,就是 Hadoop 的開始和大規模發展的地方,之后隨著 Yahoo 的牛人去了 Facebook, Google, 也有成立了 Cloudera, Hortonworks 等大數據公司,把 Hadoop 的實踐帶到各個硅谷公司。而 Google 還沒有停止,又出了新的三輛馬車,Pregel, Caffeine, Dremel, 后來又有很多步入后塵,開始新一輪開源大戰。
為啥 Hadoop 就比較適合做大數據呢?首先擴展很好,直接通過加節點就可以把系統能力提高,它有個重要思想是移動計算而不是移動數據,因為數據的移動是很大的成本需要網絡帶寬。其次它提出的目標就是利用廉價的普通計算機(硬盤),這樣雖然可能不穩定(磁盤壞的幾率),但通過系統級別上的容錯和冗余達到高可靠性。并且非常靈活,可以使用各種 data,二進制,文檔型,記錄型。使用各種形式(結構化,半結構化,非結構化所謂的 schemaless),在按需計算上也是個技巧。
7、圍繞在 Hadoop 周圍的有哪些公司和產品?
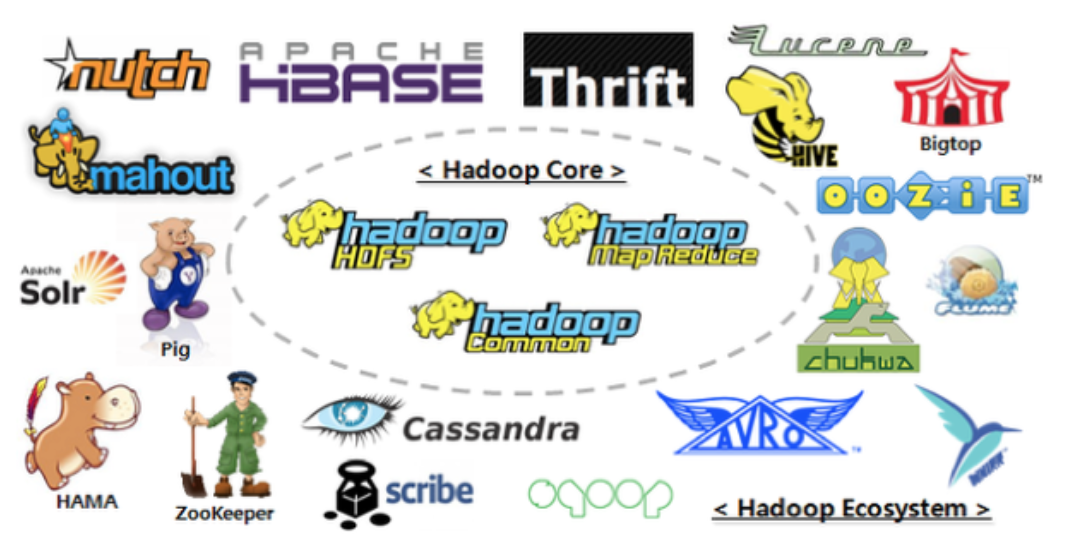
提到 Hadoop 一般不會說某一個東西,而是指生態系統,在這里面太多交互的組件了,涉及到 IO,處理,應用,配置,工作流。在真正的工作中,當幾個組件互相影響,你頭疼的維護才剛剛開始。我也簡單說幾個:Hadoop Core 就三個 HDFS,MapReduce,Common,在外圍有 NoSQL: Cassandra, HBase, 有 Facebook 開發的數據倉庫 Hive,有 Yahoo 主力研發的 Pig 工作流語言,有機器學習算法庫 Mahout,工作流管理軟件 Oozie,在很多分布式系統選擇 Master 中扮演重要角色的 Zookeeper。
8、能否用普通人都能理解的方式解釋一下 Hadoop 的工作原理?
我們先說 HDFS,所謂 Hadoop 的分布式文件系統,它是能真正做到高強度容錯。并且根據 locality 原理,對連續存儲做了優化。簡單說就是分配大的數據塊,每次連續讀整數個。如果讓你自己來設計分布式文件系統,在某機器掛掉還能正常訪問該怎么做?首先需要有個 master 作為目錄查找(就是 Namenode),那么數據節點是作為分割好一塊塊的,同一塊數據為了做備份不能放到同一個機器上,否則這臺機器掛了,你備份也同樣沒辦法找到。HDFS 用一種機架位感知的辦法,先把一份拷貝放入同機架上的機器,然后在拷貝一份到其他服務器,也許是不同數據中心的,這樣如果某個數據點壞了,就從另一個機架上調用,而同一個機架它們內網連接是非常快的,如果那個機器也壞了,只能從遠程去獲取。這是一種辦法,現在還有基于 erasure code 本來是用在通信容錯領域的辦法,可以節約空間又達到容錯的目的,大家感興趣可以去查詢。
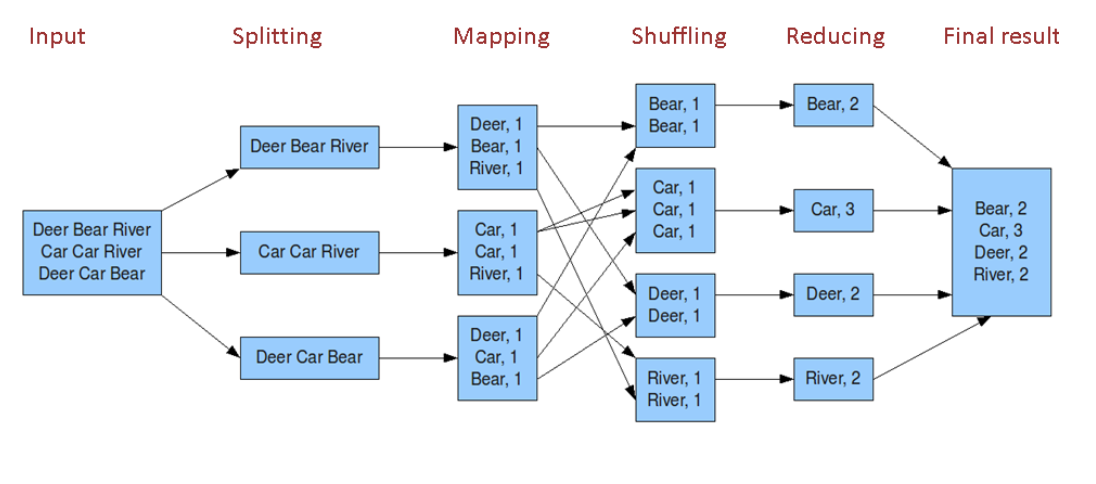
接著說 MapReduce,首先是個編程范式,它的思想是對批量處理的任務,分成兩個階段,所謂的 Map 階段就是把數據生成 key, value pair, 再排序,中間有一步叫 shuffle,把同樣的 key 運輸到同一個 reducer 上面去,而在 reducer 上,因為同樣 key 已經確保在同一個上,就直接可以做聚合,算出一些 sum, 最后把結果輸出到 HDFS 上。對應開發者來說,你需要做的就是編寫 Map 和 reduce 函數,像中間的排序和 shuffle 網絡傳輸,容錯處理,框架已經幫你做好了。
9、MapReduce 模型本身也有一些問題?
第一:需要寫很多底層的代碼不夠高效,第二:所有的事情必須要轉化成兩個操作 Map/Reduce,這本身就很奇怪,也不能解決所有的情況。
10、Spark 從何而來?Spark 相比于 Hadoop MapReduce 設計上有什么樣的優勢?
其實 Spark 出現就是為了解決上面的問題。先說一些 Spark 的起源。發自 2010 年 Berkeley AMPLab,發表在 hotcloud 是一個從學術界到工業界的成功典范,也吸引了頂級 VC:Andreessen Horowitz 的注資. 在 2013 年,這些大牛(Berkeley 系主任,MIT 最年輕的助理教授)從 Berkeley AMPLab 出去成立了 Databricks,引無數 Hadoop 大佬盡折腰,它是用函數式語言 Scala 編寫,Spark 簡單說就是內存計算(包含迭代式計算,DAG 計算, 流式計算 )框架,之前 MapReduce 因效率低下大家經常嘲笑,而 Spark 的出現讓大家很清新。 Reynod 作為 Spark 核心開發者, 介紹 Spark 性能超 Hadoop 百倍,算法實現僅有其 1/10 或 1/100。在去年的 Sort benchmark 上,Spark 用了 23min 跑完了 100TB 的排序,刷新了之前 Hadoop 保持的世界紀錄。
11、如果想從事大數據方面的工作,是否可以推薦一些有效的學習方法?有哪些推薦的書籍?
我也有一些建議,首先還是打好基礎,Hadoop 雖然是火熱,但它的基礎原理都是書本上很多年的積累,像算法導論,Unix 設計哲學,數據庫原理,深入理解計算機原理,Java 設計模式,一些重量級的書可以參考。
其次是選擇目標,如果你像做數據科學家學習 Hive,Pig 這些基本工具,如果做應用層,主要是把 Hadoop 的一些工作流要熟悉,包括一些基本調優,如果是想做架構,除了能搭建集群,對各個基礎軟件服務很了解,還要理解計算機的瓶頸和負載管理,Linux 的一些性能工具。最后還是要多加練習,大數據本身就是靠實踐的,你可以先按 API 寫書上的例子,能夠先調試成功,在下面就是多積累,當遇到相似的問題能找到對應的經典模式,再進一步就是實際問題,也許周邊誰也沒遇到,你需要些靈感和網上問問題的技巧,然后根據實際情況作出最佳選擇。
12、與大數據技術關系最緊密的就是云計算,您曾在 Amazon 云計算部門工作過,能否簡單介紹一下亞馬遜的 Redshift 框架嗎?
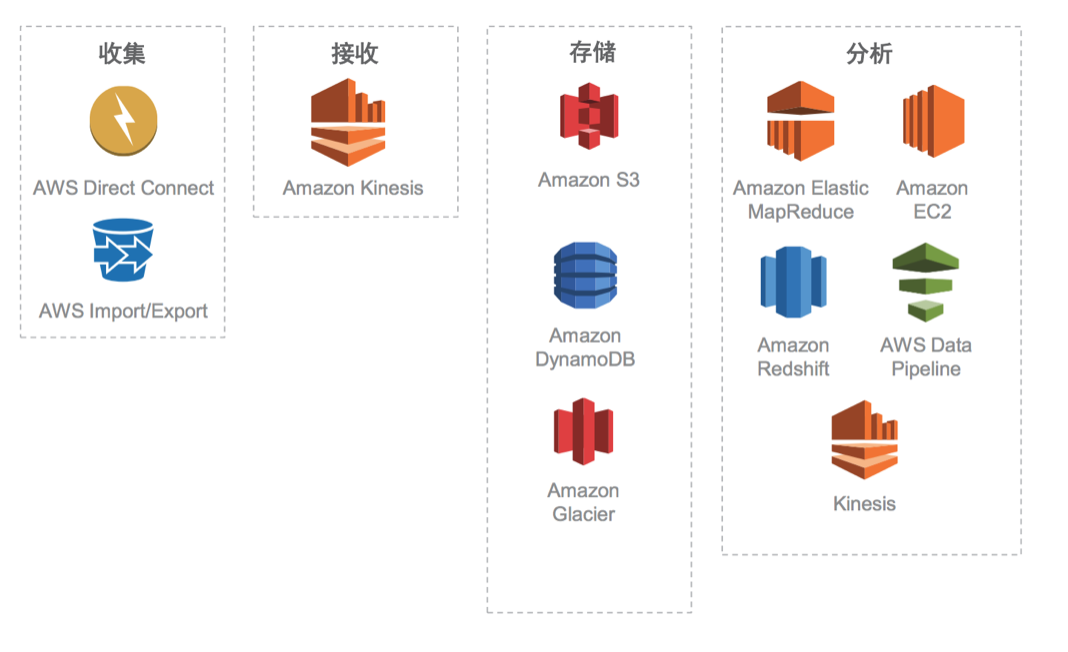
我在 Amazon 云計算部門工作過,所以還是比較了解 AWS,總體上成熟度很高,有大量 startup 是基于其開發,比如有名的 Netflix,Pinterest,Coursera。Amazon 還是不斷創新,每年召開 reInvent 大會推廣新的云產品和分享成功案例,在這里面我隨便說幾個:像 S3 是簡單面向對象的存儲,DynamoDB 是對關系型數據庫的補充,Glacier 對冷數據做歸檔處理,Elastic MapReduce 直接對 MapReduce 做打包提供計算服務,EC2 就是基礎的虛擬主機,Data Pipeline 會提供圖形化界面直接串聯工作任務。
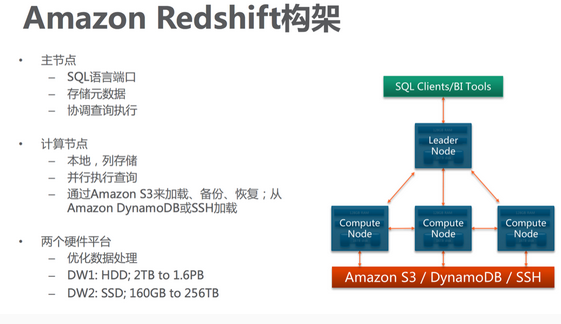
Redshift,它是一種(massively parallel computer)架構,是非常方便的數據倉庫解決方案,就是 SQL 接口,跟各個云服務無縫連接,最大特點就是快,在 TB 到 PB 級別非常好的性能,我在工作中也是直接使用,它還支持不同的硬件平臺,如果想速度更快,可以使用 SSD 的,當然支持容量就小些。
13、Linkedin 都采用了哪些大數據開源技術?
在 Linkedin,有很多數據產品,比如 People you may like, job you may be interested, 你的用戶訪問來源,甚至你的 career path 都可以挖掘出來。那么在 Linkedin 也是大量用到開源技術,我這里就說一個最成功的 Kafka,它是一個分布式的消息隊列,可以用在 tracking,機器內部 metrics,數據傳輸。數據在前端后端會經過不同的存儲或者平臺,每個平臺都有自己的格式,如果沒有一個 unified log,會出現災難型的 O (m*n) 的數據對接復雜度,如果你設定的格式一旦發生變化,也是要修改所有相關的。所以這里提出的中間橋梁就是 Kafka,大家約定用一個格式作為傳輸標準,然后在接受端可以任意定制你想要的數據源(topics), 最后實現的線性的 O (m+n) 的復雜度。對應的設計細節,Rao Jun 出來成立了 Kafka 作為獨立發展的公司。

在 Linkedin,Hadoop 作為批處理的主力,大量應用在各個產品線上,比如廣告組。我們一方面需要去做一些靈活的查詢分析廣告主的匹配,廣告預測和實際效果,另外在報表生成方面也是 Hadoop 作為支持。如果你想去面試 Linkedin 后端組,我建議大家去把 Hive, Pig, Azkaban (數據流的管理軟件),Avro 數據定義格式,Kafka,Voldemort 都去看一些設計理念,Linkedin 有專門的開源社區,也是 build 自己的技術品牌。
14、談一談 Coursera 在大數據架構方面和其他硅谷創業公司相比有什么特點?是什么原因和技術取向造成了這些特點?

Coursera 是一個有使命驅動的公司,大家不是為了追求技術的極致,而是為了服務好老師,同學,解決他們的痛點,分享他們的成功。這點是跟其他技術公司最大的區別。從一方面來說,現在還是早期積累階段,大規模計算還沒有來臨,我們只有積極學習,適應變化才能保持創業公司的高速成長。
Coursera 作為創業公司,非常想保持敏捷和高效。從技術上來說,所有的都是在基于 AWS 開發,可以想像隨意啟動云端服務,做一些實驗。我們大致分成產品組,架構組,和數據分析組。我把所有用到的開發技術都列在上面。因為公司比較新,所以沒有什么歷史遺留遷移的問題。大家大膽的使用 Scala 作為主要編程語言,采用 Python 作為腳本控制,比如產品組就是提供的課程產品,里面大量使用 Play Framework,Javascript 的 backbone 作為控制中樞。而架構組主要是維護底層存儲,通用服務,性能和穩定性。
我在的數據組由 10 多人構成,一部分是對商業產品,核心增長指標做監控,挖掘和改進。一部分是搭建數據倉庫完善跟各個部門的無縫數據流動,也用到很多技術例如使用 Scalding 編寫 Hadoop MapReduce 程序,也有人做 AB testing 框架, 推薦系統,盡可能用最少人力做影響力的事情。其實除了開源世界,我們也積極使用第三方的產品,比如 sumologic 做日志錯誤分析,Redshift 作為大數據分析平臺,Slack 做內部通訊。而所有的這些就是想解放生產力,把重心放到用戶體驗,產品開發和迭代上去。
1、目前硅谷最火最有名的高科技創業公司都有哪些?
在硅谷大家非常熱情的談創業談機會,我也通過自己的一些觀察和積累,看到了不少最近幾年涌現的熱門創業公司。我給大家一個列表,這個是華爾街網站的全世界創業公司融資規模評選。它本來的標題是 billion startup club,我在去年國內講座也分享過,不到一年的時間,截至到 2015 年 1 月 17 日,現在的排名和規模已經發生了很大的變化。
首先估值在 10 Billlon 的達到了 7 家,而一年前一家都沒有。第二;第一名是中國人家喻戶曉的小米;第三,前20名中,絕大多數(8 成在美國,在加州,在硅谷,在舊金山!)比如 Uber, Airbnb, Dropbox, Pinterest;第四,里面也有不少相似模式成功的,比如 Flipkart 就是印度市場的淘寶,Uber 與 Airbnb 都是共享經濟的范疇。所以大家還是可以在移動 (Uber),大數據(Palantir),消費級互聯網,通訊 (Snapchat),支付 (Square),O2O App 里面尋找下大機會。這里面很多公司我都親自面試和感受過他們的環境。
2、有如此之多的高估值公司,是否意味著存在很大的泡沫?
看了那么多高估值公司,很多人都覺得非常瘋狂,這是不是很大泡沫了,泡沫是不是要破了,是很多人的疑問。我認為在硅谷這個充滿夢想的地方,投資人鼓勵創業者大膽去做同樣也助長了泡沫,很多項目在幾個月的時間就會估值翻 2,3 倍,如 Uber,Snapchat 上我也驚訝于他們的巨額融資規模。那么這張圖就是講“新興技術炒作”周期,把各類技術按照技術成熟度和期望值分類。
創新萌芽 Innovation Trigger”、“期望最頂點 Peak ofInflated Expectation”、“下調預期至低點 Trough of Disillusion”、“回歸理想 Slope ofEnlightenment”、“生產率平臺 Plateau of Productivity”,越往左,技術約新潮,越處于概念階段;越往右,技術約成熟,約進入商業化應用,發揮出提高生產率的效果。縱軸代表預期值,人們對于新技術通常會隨著認識的深入,預期不斷升溫,伴之以媒體炒作而到達頂峰;隨之因技術瓶頸或其他原因,預期逐漸冷卻至低點,但技術技術成熟后,期望又重新上升,重新積累用戶,然后就到了可持續增長的健康軌道上來。
Gartner 公司每年發布技術趨勢炒作圖。今年和去年的圖對比顯示,物聯網、自動駕駛汽車、消費級 3D 打印、自然語言問答等概念正在處于炒作的頂峰。而大數據已從頂峰滑落,NFC 和云計算接近谷底。
3、未來,高科技創業的趨勢是什么?
我先提一個最近看的一部電影《Imitation Game》,講計算機邏輯的奠基者艾倫圖靈(計算機屆最高獎以他命名)艱難的一生,他當年為破譯德軍密碼制作了圖靈機為二戰勝利作出卓越貢獻,挽回幾千萬人的生命,可在那個時代因為同性戀被判化學閹割,自殺結束了短暫的 42 歲生命。他的一個偉大貢獻就是在人工智能的開拓工作,他提出圖靈測試(Turing Test),測試某機器是否能表現出與人等價或無法區分的智能。
今天人工智能已經有了很大進步,從專家系統到基于統計的學習,從支持向量機到神經網絡深度學習,每一步都帶領機器智能走向下一個階梯。
在 Google 資深科學家吳軍博士(數學之美,浪潮之巔作者),他提出當前技術發展三個趨勢,第一,云計算和和移動互聯網,這是正在進行時;第二,機器智能,現在開始發生,但對社會的影響很多人還沒有意識到;第三,大數據和機器智能結合,這是未來時,一定會發生,有公司在做,但還沒有太形成規模。他認為未來機器會控制 98% 的人,而現在我們就要做個選擇,怎么成為剩下的 2%?
4、為什么大數據和機器智能結合的未來一定會到來?
其實在工業革命之前(1820 年),世界人均 GDP 在 1800 年前的兩三千年里基本沒有變化,而從 1820 年到 2001 年的 180 年里,世界人均 GDP 從原來的 667 美元增長到 6049 美元。由此足見,工業革命帶來的收入增長的確是翻天覆地的。這里面發生了什么,大家可以去思考一下。但人類的進步并沒有停止或者說穩步增長,在發明了電力,電腦,互聯網,移動互聯網,全球年 GDP 增長從萬分之 5 到 2%,信息也是在急劇增長,根據計算,最近兩年的信息量是之前 30 年的總和,最近 10 年是遠超人類所有之前累計信息量之和。在計算機時代,有個著名的摩爾定律,就是說同樣成本每隔 18 個月晶體管數量會翻倍,反過來同樣數量晶體管成本會減半,這個規律已經很好的 match 了最近 30 年的發展,并且可以衍生到很多類似的領域:存儲、功耗、帶寬、像素。
馮諾伊曼是 20 世紀最重要的數學家之一,在現代計算機、博弈論和核武器等諸多領域內有杰出建樹的最偉大的科學全才之一。他提出(技術)將會逼近人類歷史上的某種本質的奇點,在那之后全部人類行為都不可能以我們熟悉的面貌繼續存在。這就是著名的奇點理論。目前會越來越快指數性增長,美國未來學家 Ray Kurzweil 稱人類能夠在 2045 年實現數字化永生,他自己也創辦奇點大學,相信隨著信息技術、無線網、生物、物理等領域的指數級增長,將在 2029 年實現人工智能,人的壽命也將會在未來 15 年得到大幅延長。
5、國外值得關注的大數據公司都有哪些?國內又有哪些?
這是 2014 年總結的 Big Data 公司列表,我們大致可以分成基礎架構和應用,而底層都是會用到一些通用技術,如 Hadoop,Mahout,HBase,Cassandra,我在下面也會涵蓋。我可以舉幾個例子,在分析這一塊,cloudera,hortonworks,mapr 作為 Hadoop 的三劍客,一些運維領域,mangodb,couchbase 都是 nosql 的代表,作為服務領域 AWS 和 Google BigQuery 劍拔弩張,在傳統數據庫,Oracle 收購了 MySQL,DB2 老牌銀行專用,Teradata 做了多年數據倉庫。上面的 Apps 更多,比如社交消費領域 Google, Amazon, Netflix, Twitter, 商業智能:SAP,GoodData,一些在廣告媒體領域:TURN,Rocketfuel,做智能運維 sumologic 等等。去年的新星 Databricks 伴隨著 Spark 的浪潮震撼 Hadoop 的生態系統。
對于迅速成長的中國市場,大公司也意味著大數據,BAT 三家都是對大數據的投入也是不惜余力。
我 5 年前在百度的時候,就提出框計算的東東,最近兩年他們成立了硅谷研究院,挖來 Andrew Ng 作為首席科學家,研究項目就是百度大腦,在語音、圖片識別大幅提高精確度和召回率,最近還做了個無人自行車,非常有趣。騰訊作為最大的社交應用對大數據也是情有獨鐘,自己研發了 C++ 平臺的海量存儲系統。淘寶去年雙十一主戰場,2 分鐘突破 10 億,交易額突破 571 億,背后是有很多故事,當年在百度做 Pyramid(按 Google 三輛馬車打造的金字塔三層分布式系統)的有志之士,繼續在 OceanBase 創造神話。而阿里云當年備受爭議,馬云也懷疑是不是被王堅忽悠,最后經歷了雙十一的洗禮證明了阿里云的靠譜。小米的雷軍對大數據也是寄托厚望,一方面這么多數據幾何級數增長,另一方面存儲帶寬都是巨大成本,沒價值就會破產。
6、Hadoop 是現今最流行的大數據技術,在它出現的當時,是什么造成了 Hadoop 的流行?當時 Hadoop 具有哪些設計上的優勢?
看 Hadoop 從哪里開始的,不得不提 Google 的先進性,在 10 多年前,Google 出了 3 篇 paper 論述分布式系統的做法,分別是 GFS, MapReduce, BigTable, 非常 NB 的系統,但沒人見過,在工業界很多人癢癢的就想按其思想去仿作,當時 Apache Nutch Lucene 的作者 Doug Cutting 也是其中之一,后來他們被 Yahoo 收購,專門成立 Team 去投入做,就是 Hadoop 的開始和大規模發展的地方,之后隨著 Yahoo 的牛人去了 Facebook, Google, 也有成立了 Cloudera, Hortonworks 等大數據公司,把 Hadoop 的實踐帶到各個硅谷公司。而 Google 還沒有停止,又出了新的三輛馬車,Pregel, Caffeine, Dremel, 后來又有很多步入后塵,開始新一輪開源大戰。
為啥 Hadoop 就比較適合做大數據呢?首先擴展很好,直接通過加節點就可以把系統能力提高,它有個重要思想是移動計算而不是移動數據,因為數據的移動是很大的成本需要網絡帶寬。其次它提出的目標就是利用廉價的普通計算機(硬盤),這樣雖然可能不穩定(磁盤壞的幾率),但通過系統級別上的容錯和冗余達到高可靠性。并且非常靈活,可以使用各種 data,二進制,文檔型,記錄型。使用各種形式(結構化,半結構化,非結構化所謂的 schemaless),在按需計算上也是個技巧。
7、圍繞在 Hadoop 周圍的有哪些公司和產品?
提到 Hadoop 一般不會說某一個東西,而是指生態系統,在這里面太多交互的組件了,涉及到 IO,處理,應用,配置,工作流。在真正的工作中,當幾個組件互相影響,你頭疼的維護才剛剛開始。我也簡單說幾個:Hadoop Core 就三個 HDFS,MapReduce,Common,在外圍有 NoSQL: Cassandra, HBase, 有 Facebook 開發的數據倉庫 Hive,有 Yahoo 主力研發的 Pig 工作流語言,有機器學習算法庫 Mahout,工作流管理軟件 Oozie,在很多分布式系統選擇 Master 中扮演重要角色的 Zookeeper。
8、能否用普通人都能理解的方式解釋一下 Hadoop 的工作原理?
我們先說 HDFS,所謂 Hadoop 的分布式文件系統,它是能真正做到高強度容錯。并且根據 locality 原理,對連續存儲做了優化。簡單說就是分配大的數據塊,每次連續讀整數個。如果讓你自己來設計分布式文件系統,在某機器掛掉還能正常訪問該怎么做?首先需要有個 master 作為目錄查找(就是 Namenode),那么數據節點是作為分割好一塊塊的,同一塊數據為了做備份不能放到同一個機器上,否則這臺機器掛了,你備份也同樣沒辦法找到。HDFS 用一種機架位感知的辦法,先把一份拷貝放入同機架上的機器,然后在拷貝一份到其他服務器,也許是不同數據中心的,這樣如果某個數據點壞了,就從另一個機架上調用,而同一個機架它們內網連接是非常快的,如果那個機器也壞了,只能從遠程去獲取。這是一種辦法,現在還有基于 erasure code 本來是用在通信容錯領域的辦法,可以節約空間又達到容錯的目的,大家感興趣可以去查詢。
接著說 MapReduce,首先是個編程范式,它的思想是對批量處理的任務,分成兩個階段,所謂的 Map 階段就是把數據生成 key, value pair, 再排序,中間有一步叫 shuffle,把同樣的 key 運輸到同一個 reducer 上面去,而在 reducer 上,因為同樣 key 已經確保在同一個上,就直接可以做聚合,算出一些 sum, 最后把結果輸出到 HDFS 上。對應開發者來說,你需要做的就是編寫 Map 和 reduce 函數,像中間的排序和 shuffle 網絡傳輸,容錯處理,框架已經幫你做好了。
9、MapReduce 模型本身也有一些問題?
第一:需要寫很多底層的代碼不夠高效,第二:所有的事情必須要轉化成兩個操作 Map/Reduce,這本身就很奇怪,也不能解決所有的情況。
10、Spark 從何而來?Spark 相比于 Hadoop MapReduce 設計上有什么樣的優勢?
其實 Spark 出現就是為了解決上面的問題。先說一些 Spark 的起源。發自 2010 年 Berkeley AMPLab,發表在 hotcloud 是一個從學術界到工業界的成功典范,也吸引了頂級 VC:Andreessen Horowitz 的注資. 在 2013 年,這些大牛(Berkeley 系主任,MIT 最年輕的助理教授)從 Berkeley AMPLab 出去成立了 Databricks,引無數 Hadoop 大佬盡折腰,它是用函數式語言 Scala 編寫,Spark 簡單說就是內存計算(包含迭代式計算,DAG 計算, 流式計算 )框架,之前 MapReduce 因效率低下大家經常嘲笑,而 Spark 的出現讓大家很清新。 Reynod 作為 Spark 核心開發者, 介紹 Spark 性能超 Hadoop 百倍,算法實現僅有其 1/10 或 1/100。在去年的 Sort benchmark 上,Spark 用了 23min 跑完了 100TB 的排序,刷新了之前 Hadoop 保持的世界紀錄。
11、如果想從事大數據方面的工作,是否可以推薦一些有效的學習方法?有哪些推薦的書籍?
我也有一些建議,首先還是打好基礎,Hadoop 雖然是火熱,但它的基礎原理都是書本上很多年的積累,像算法導論,Unix 設計哲學,數據庫原理,深入理解計算機原理,Java 設計模式,一些重量級的書可以參考。
其次是選擇目標,如果你像做數據科學家學習 Hive,Pig 這些基本工具,如果做應用層,主要是把 Hadoop 的一些工作流要熟悉,包括一些基本調優,如果是想做架構,除了能搭建集群,對各個基礎軟件服務很了解,還要理解計算機的瓶頸和負載管理,Linux 的一些性能工具。最后還是要多加練習,大數據本身就是靠實踐的,你可以先按 API 寫書上的例子,能夠先調試成功,在下面就是多積累,當遇到相似的問題能找到對應的經典模式,再進一步就是實際問題,也許周邊誰也沒遇到,你需要些靈感和網上問問題的技巧,然后根據實際情況作出最佳選擇。
12、與大數據技術關系最緊密的就是云計算,您曾在 Amazon 云計算部門工作過,能否簡單介紹一下亞馬遜的 Redshift 框架嗎?
我在 Amazon 云計算部門工作過,所以還是比較了解 AWS,總體上成熟度很高,有大量 startup 是基于其開發,比如有名的 Netflix,Pinterest,Coursera。Amazon 還是不斷創新,每年召開 reInvent 大會推廣新的云產品和分享成功案例,在這里面我隨便說幾個:像 S3 是簡單面向對象的存儲,DynamoDB 是對關系型數據庫的補充,Glacier 對冷數據做歸檔處理,Elastic MapReduce 直接對 MapReduce 做打包提供計算服務,EC2 就是基礎的虛擬主機,Data Pipeline 會提供圖形化界面直接串聯工作任務。
Redshift,它是一種(massively parallel computer)架構,是非常方便的數據倉庫解決方案,就是 SQL 接口,跟各個云服務無縫連接,最大特點就是快,在 TB 到 PB 級別非常好的性能,我在工作中也是直接使用,它還支持不同的硬件平臺,如果想速度更快,可以使用 SSD 的,當然支持容量就小些。
13、Linkedin 都采用了哪些大數據開源技術?
在 Linkedin,有很多數據產品,比如 People you may like, job you may be interested, 你的用戶訪問來源,甚至你的 career path 都可以挖掘出來。那么在 Linkedin 也是大量用到開源技術,我這里就說一個最成功的 Kafka,它是一個分布式的消息隊列,可以用在 tracking,機器內部 metrics,數據傳輸。數據在前端后端會經過不同的存儲或者平臺,每個平臺都有自己的格式,如果沒有一個 unified log,會出現災難型的 O (m*n) 的數據對接復雜度,如果你設定的格式一旦發生變化,也是要修改所有相關的。所以這里提出的中間橋梁就是 Kafka,大家約定用一個格式作為傳輸標準,然后在接受端可以任意定制你想要的數據源(topics), 最后實現的線性的 O (m+n) 的復雜度。對應的設計細節,Rao Jun 出來成立了 Kafka 作為獨立發展的公司。
在 Linkedin,Hadoop 作為批處理的主力,大量應用在各個產品線上,比如廣告組。我們一方面需要去做一些靈活的查詢分析廣告主的匹配,廣告預測和實際效果,另外在報表生成方面也是 Hadoop 作為支持。如果你想去面試 Linkedin 后端組,我建議大家去把 Hive, Pig, Azkaban (數據流的管理軟件),Avro 數據定義格式,Kafka,Voldemort 都去看一些設計理念,Linkedin 有專門的開源社區,也是 build 自己的技術品牌。
14、談一談 Coursera 在大數據架構方面和其他硅谷創業公司相比有什么特點?是什么原因和技術取向造成了這些特點?
Coursera 是一個有使命驅動的公司,大家不是為了追求技術的極致,而是為了服務好老師,同學,解決他們的痛點,分享他們的成功。這點是跟其他技術公司最大的區別。從一方面來說,現在還是早期積累階段,大規模計算還沒有來臨,我們只有積極學習,適應變化才能保持創業公司的高速成長。
Coursera 作為創業公司,非常想保持敏捷和高效。從技術上來說,所有的都是在基于 AWS 開發,可以想像隨意啟動云端服務,做一些實驗。我們大致分成產品組,架構組,和數據分析組。我把所有用到的開發技術都列在上面。因為公司比較新,所以沒有什么歷史遺留遷移的問題。大家大膽的使用 Scala 作為主要編程語言,采用 Python 作為腳本控制,比如產品組就是提供的課程產品,里面大量使用 Play Framework,Javascript 的 backbone 作為控制中樞。而架構組主要是維護底層存儲,通用服務,性能和穩定性。
我在的數據組由 10 多人構成,一部分是對商業產品,核心增長指標做監控,挖掘和改進。一部分是搭建數據倉庫完善跟各個部門的無縫數據流動,也用到很多技術例如使用 Scalding 編寫 Hadoop MapReduce 程序,也有人做 AB testing 框架, 推薦系統,盡可能用最少人力做影響力的事情。其實除了開源世界,我們也積極使用第三方的產品,比如 sumologic 做日志錯誤分析,Redshift 作為大數據分析平臺,Slack 做內部通訊。而所有的這些就是想解放生產力,把重心放到用戶體驗,產品開發和迭代上去。
- 北京機房搬遷改造公司,系統集成有哪些公司?-2019-11-04
- 如何打造一個安全的網絡環境?政府要做到這四點-2019-11-04
- 北京辦公室網絡布線,綜合布線施工價格-2019-11-04
- 深信服產品專業上網行為管理,安全設備有保障-2019-11-04
- 兩年內網絡安全市場規模將達千億級別?來看看詳細分析-2019-11-04
- 北京炫億時代專業機房設備除塵,機房網絡改造-2019-11-04
- 企業如何保障移動辦公的安全性?移動辦公存在的七大安-2019-11-01
- 北京深信服AC-1000-A400產品租賃購買,專業IT上網行為管理-2019-11-01
- 互聯網企業軟件開發如何才能沒有漏洞?專業工程師給出-2019-11-01
- 如何避免APP的“越權”行為?要靠制定相關法律法規-2019-11-01
 企業通訊
企業通訊
